玉渊谭天丨热解读:为何DeepSeek引发美国恐慌
2025-01-28 17:01 玉渊谭天
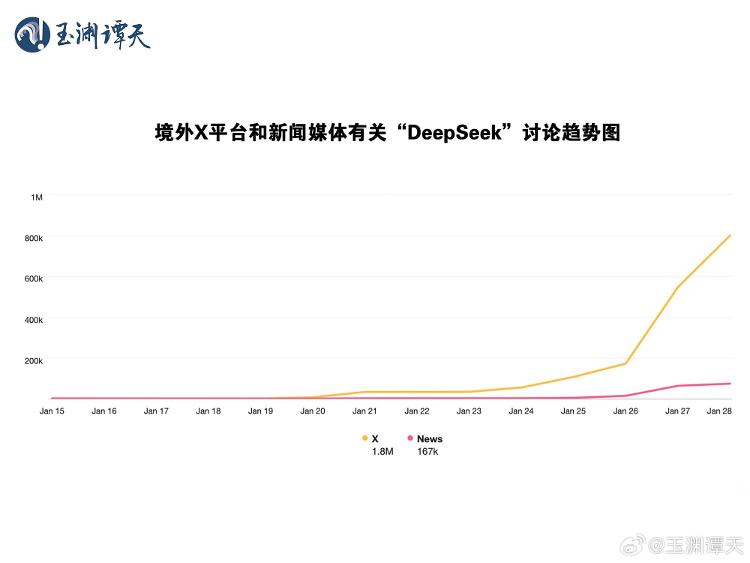
DeepSeek开发成本与美国大模型相比大幅降低,在于应用了不同的模型训练模式,打破了美国堆砌算力的“豪气”方式。在喂养学习数据这一大模型重要环节上,OpenAI选择了“人海战术”,堆砌算卡、将资源集中在算力,用海量数据投喂实现能力的提升。而DeepSeek相比于“砸资源”选择了另外一种方式。利用算法把数据进行总结和分类,经过选择性处理之后再输送给大模型,最大优化算力实现了成本的降低和模型性能提升。目前看Meta耗费了大量资金训练Llama,但是效果上却没有成本极低的DeepSeek效果好,Meta高层已经在思考其员工是否在浪费公司资金,而这也引发了不少企业技术人员的恐慌,他们担心自己被质疑技术能力和创新性从而失去工作。根据海外互联网平台对DeepSeek的讨论分析,社交媒体帖子的数量远高于新闻报道,数量约是新闻报道的十倍。时间上来看,社交媒体帖子的讨论早于新闻报道,发酵起点比新闻媒体早了五天,这是由从事科技工作的自媒体人以及员工圈层传播“破圈”造成。
原因三:
国产大模型正在厚积薄发