性能超越DeepSeek-OCR2,百度发布并开源新一代SOTA OCR模型
2026-01-30 10:32 海报新闻
1月29日,百度正式发布并开源新一代文档解析模型PaddleOCR-VL-1.5。该模型以仅0.9B参数的轻量架构,在全球权威文档解析评测榜单OmniDocBench V1.5中取得全球综合性能第一成绩,整体精度达到94.5%,超过Gemini-3-Pro、DeepSeek-OCR2、Qwen3-VL-235B-A22B、GPT-5.2等模型。
值得关注的是,PaddleOCR-VL-1.5 全球首次实现OCR模型的“异形框定位”能力,使机器能够精准识别倾斜、弯折、拍照畸变等非规则文档形态,首次让“歪文档”实现稳定、可规模化解析。该技术解决了传统OCR模型在移动拍照、扫描件变形、复杂光照等真实场景中因文档形变导致的识别失败问题,可广泛应用于金融票据处理、档案数字化、政务文档流转等场景。
PaddleOCR-VL-1.5 基于文心大模型进行开发,在 OmniDocBench V1.5多个关键指标上取得领先表现。其中,表格结构理解(92.8 分)和阅读顺序预测(95.8 分)两项核心指标上均位列第一,分别领先 Gemini-3-Pro、DeepSeek-OCR 等主流模型 2–5 分不等。在文档阅读顺序预测任务中,其版面逻辑解析错误率仅为同类其他模型约一半。这表明,PaddleOCR-VL-1.5 在复杂文档结构还原与版面逻辑理解方面具备更高稳定性,在合同、财报等高复杂度业务场景中拥有更高可用性。
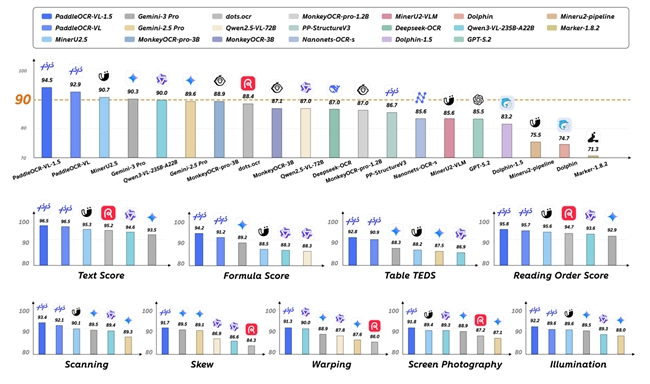
2025年10月16日,百度首次发布并开源 PaddleOCR-VL模型,在 OmniDocBench V1.5 榜单中取得全球SOTA成绩,并连续五天登顶 HuggingFace全球模型总趋势榜与ModelScope全球模型总趋势榜双榜第一。